AI摘要:先看结论:Opus 4.8 赢在复杂闭环,不赢在所有场景 如果只想快速选型,可以把三款模型粗略分成三类:
模型更适合什么任务主要优势需要付出的代价Claude Opus 4.8长上下文代码库、复杂重构、多步 Agent、需要自检的高风险任务SWE-bench Pro、GDPVal-AA、缺陷发现、诚实性高 effort 会增加 token 和时延,动态子代理跑偏时扩散也更快GPT-5.5终端开发、快速原型、高频短回路实现TerminalBench模型 / 档位输入价格(美元 / 百万 tokens)输出价格(美元 / 百万 tokens)适合的预算策略Opus 4.8 标准525日常复杂任务主力档Opus 4.8 Fast1050需要低延迟或更强执行链路时开启Opus 4.7 标准525稳定生产底座Opus 4.7 Fast30150成本压力较大,更适合少量关键任务GPT-5.5 标准530常规开发与通用任务GPT-5.5 Pro30180高性能场景,但账单上升很快 这里的变化不是“便宜了一点”这么简单。模型隐藏税本质Opus 4.8高 effort 抬高 token 和时延;动态子代理增加 orchestration 复杂度;更强 guardrail 可能让边界任务更难跑把预算花在少犯错和能交付上GPT-5.5Pro 档昂贵;执行风格更激进;需要团队自己补风险控制把预算花在速度和推进力上Opus 4.7hardest task 胜率上限被拉开;大规模 Agent 回路会更快碰到天花板税在机会成本上 如果团队只盯显性价格,会误判。
从价格、基准、动态工作流和诚实性,看 Opus 4.8 如何提升复杂 Agent 交付率。 原文链接:AI小老六
2026 年 5 月 28 日,Anthropic 发布 Claude Opus 4.8。乍看这次更新不算“戏剧化”:标准价格没有上涨,上下文窗口也没有继续用更夸张的数字刷存在感。
但如果只按“窗口有没有变大、价格有没有变贵、参数有没有更多”去看 Opus 4.8,很容易看偏。它真正动刀的地方,是复杂 Agent 任务里最烦人的几件事:多步任务能不能收敛,代码修改能不能验证,模型知道不知道自己哪里没把握,以及团队能不能把高算力模式纳入日常成本表。
一句话概括:Opus 4.8 不是为了让模型看起来更会聊天,而是为了让它在长链路任务里更像一个愿意交付、会复核、知道风险边界的工程执行者。
如果只想快速选型,可以把三款模型粗略分成三类:
所以 **Opus 4.8 不是“所有维度碾压”**。它的优势很明确:更复杂、更长、更需要自我校验的任务,它更值得上;如果只是终端里小步快跑,GPT-5.5 依然很有吸引力;如果已有流程跑得稳,Opus 4.7 也没有突然过时。
Opus 4.8 的标准 API 价格仍是输入 5 美元、输出 25 美元每百万 tokens,和 Opus 4.7 持平。这个信息比看起来更重要:Anthropic 没有把新旗舰做成“涨价换性能”。
真正值得盯的是 Fast mode。Opus 4.8 Fast 调整到输入 10 美元、输出 50 美元每百万 tokens;相比上一代高性能快链路,价格下探很多。它不再像一个偶尔救火才开的奢侈开关,而是可以进入团队的任务成本模型。
这里的变化不是“便宜了一点”这么简单。对企业团队来说,模型是否能进入流水线,取决于它能不能被预算化。Prompt Caching、Batch API、地域推理溢价这些条款,往往比单次 demo 的表现更决定最终采用率。
Opus 4.8 的 Fast mode 价格下探后,团队终于可以更认真地问一个问题:这类任务多花一点 token 和时延,换更高完成率,是否划算?以前这个问题经常不用算,因为太贵。
公开指标里,有三组数字最能说明 Opus 4.8 的定位。
这三项放在一起,结论很清楚:Opus 4.8 的强项不是“终端里每一步都最快”,而是“复杂任务更容易走到可交付结果”。
SWE-bench Pro 尤其值得看。它不是让模型补一个玩具函数,而是要求模型在真实代码库里理解上下文、改多个文件、跑验证、修问题。Opus 4.8 在这类测试里领先,说明它在“读仓库 → 拆问题 → 写 patch → 自检”的链路上更稳。
但 TerminalBench 2.1 又把另一个事实摆出来:GPT-5.5 在终端型编码里仍然更强。它更像一个反应快、手感猛、愿意快速推进的 CLI 搭档。Opus 4.8 则更像一个不会那么着急、但更愿意把事情查清楚再交付的工程同事。
更实用的模型选择方式,不是把所有分数加权求和,而是先判断任务失败一次的代价。
图:按失败成本、终端速度和既有流程选择模型。
如果任务失败会带来昂贵返工,比如跨模块重构、核心业务代码、金融分析、法律材料、长链路 Agent 执行,Opus 4.8 的价值会更明显。它慢一点、贵一点,可能反而省钱,因为少返工。
如果任务允许快速试错,比如写脚本、搭原型、终端里反复跑小改动,GPT-5.5 的速度感更直接。这个场景下,“先冲起来”比“每一步都自证清白”更重要。
如果团队已经在 Opus 4.7 上有稳定工作流,不需要马上追 hardest benchmark,那也没必要为了新模型立刻迁移。4.8 拉高的是上限,不是把 4.7 的地板抽走。
Opus 4.8 配套强调的 Dynamic Workflows,不只是一个新名词。它真正改变的是任务执行方式:模型可以在运行中拆 plan、调子代理、并行探索、汇总冲突,再决定是否重试或交付。
这对 coding 很关键。因为真实软件任务很少是“一问一答”:你要读旧代码、理解约束、生成 patch、跑测试、解释失败、再改一轮。有时还要同时查文档、审查 diff、确认边界条件。
图:Dynamic Workflows 把复杂任务拆成规划、探索、实现、测试和复核。
Dynamic Workflows 的好处是明显的:复杂任务可以被拆开并行处理,模型不必把所有事情塞进一条单线程推理里。
但它也有影子成本。一旦 Planner 的方向错了,多个子代理会一起朝错方向努力,错误扩散速度比过去更快。以前 Agent 跑偏像一个初级工程师犯错;现在更像自动化流水线参数配错,一口气生产出一堆看起来完整但方向不对的结果。
所以 Opus 4.8 越强,团队越需要配套回滚、日志、预算上限和人工 review。否则你得到的不是“更可靠的 Agent”,而是“更快放大的错误”。
图:动态子代理能放大执行效率,也会放大错误方向。
Opus 4.8 另一个实际价值,是把 effort 显式化。
过去很多模型也会“更认真地想”,但这种认真常常是黑箱副作用:什么时候多想、想多久、花多少钱,用户事后才从延迟和账单里感受到。
Effort Control 的意义在于,你可以把任务分层:
这对工程组织很重要。模型能力进入生产,不是靠“大家感觉它更强”,而是靠任务类型、预算、延迟和失败成本之间有一套能执行的规则。Opus 4.8 把这件事往前推了一步。
Anthropic 把 Honesty / Self-check 放到 Opus 4.8 的核心卖点里,这不是装饰。
很多团队现在不缺“能写代码”的模型。真正消耗时间的是另一件事:模型到底有没有完成?有没有跑测试?有没有把失败藏起来?有没有把不确定的结论说得像已经验证过?
Opus 4.8 的价值在这里变得很具体。官方材料提到,它在代码缺陷检测上相比 4.7 有大幅提升,未发现编码错误的概率下降;外部讨论也普遍把它描述成更愿意暴露风险、更少假装完成的模型。
这种能力不一定让 demo 更炫,但会让生产环境更省心。一个模型如果能主动说:这里没验证、这个假设可能错、这段 patch 需要额外测试,它的工程价值会比单纯“写得快”高很多。
图:诚实性让模型把不确定性暴露给工程流程,而不是藏在交付结果里。
这也是 Opus 4.8 和 GPT-5.5 的风格分歧。GPT-5.5 更像冲刺型选手:推进快,试错快,工具链顺。Opus 4.8 更像审慎型执行者:慢一点,但更愿意把风险摊开讲。
没有免费的优势。三款模型都要交税,只是税种不同。
如果团队只盯显性价格,会误判。真正该算的是:一次失败要返工多久?一次跑偏会影响多少文件?一次不诚实的“已完成”会让人类 review 多花多少时间?
Opus 4.8 最强的地方,不是某一个 benchmark 数字,而是几件事叠在一起:
这些能力组合起来,才让它在企业级 Agent 任务里更像一个生产模型。
但它也不是无脑首选。Opus 4.8 的优势需要几个前提:任务足够复杂,团队能承受更高 token 和延迟,工作流里有日志、回滚、review 和预算控制。如果这些条件不成立,它的优势会被削弱。
Claude Opus 4.8 这次升级,最值得记住的不是窗口、参数或某个单项分数,而是 Anthropic 明确把模型往“复杂任务交付系统”方向推了一步。
它更适合那些失败成本高、需要多步计划、需要验证和自报风险的任务。它不一定让每一次交互都最快,但会让复杂任务更有机会走到一个可信的终点。
如果说 GPT-5.5 更像一个终端里跑得很快的工程师,Opus 4.8 更像一个会先拆方案、调人手、查风险、最后带着测试结果来交付的技术负责人。
这不是谁完全取代谁的问题。模型选型正在从“哪个最强”变成“哪个失败模式最适合我的业务”。在这个维度上,Opus 4.8 的答案很清楚:少一点炫技,多一点交付。
RAG 负责召回,LLM Wiki 负责沉淀:团队知识系统为什么不能只做检索
Agent Harness 架构真相:Prompt Cache 如何决定 Skill、MCP 与 SubAgent 设计
Claude Code 如何压缩上下文:Microcompact、Prompt Cache 与 cache_edits 工程拆解
为什么 AI Coding 难进生产环境?深入了解 Everything-Claude-Code!
当用户觉得 Agent 变笨时,真正退化的往往不是模型
暂无回复,快来抢沙发吧!
本次需消耗银元:
100
当前账户余额: 0 银元
模型更适合什么任务主要优势需要付出的代价Claude Opus 4.8长上下文代码库、复杂重构、多步 Agent、需要自检的高风险任务SWE-bench Pro、GDPVal-AA、缺陷发现、诚实性高 effort 会增加 token 和时延,动态子代理跑偏时扩散也更快GPT-5.5终端开发、快速原型、高频短回路实现TerminalBench模型 / 档位输入价格(美元 / 百万 tokens)输出价格(美元 / 百万 tokens)适合的预算策略Opus 4.8 标准525日常复杂任务主力档Opus 4.8 Fast1050需要低延迟或更强执行链路时开启Opus 4.7 标准525稳定生产底座Opus 4.7 Fast30150成本压力较大,更适合少量关键任务GPT-5.5 标准530常规开发与通用任务GPT-5.5 Pro30180高性能场景,但账单上升很快 这里的变化不是“便宜了一点”这么简单。模型隐藏税本质Opus 4.8高 effort 抬高 token 和时延;动态子代理增加 orchestration 复杂度;更强 guardrail 可能让边界任务更难跑把预算花在少犯错和能交付上GPT-5.5Pro 档昂贵;执行风格更激进;需要团队自己补风险控制把预算花在速度和推进力上Opus 4.7hardest task 胜率上限被拉开;大规模 Agent 回路会更快碰到天花板税在机会成本上 如果团队只盯显性价格,会误判。
2026 年 5 月 28 日,Anthropic 发布 Claude Opus 4.8。乍看这次更新不算“戏剧化”:标准价格没有上涨,上下文窗口也没有继续用更夸张的数字刷存在感。
但如果只按“窗口有没有变大、价格有没有变贵、参数有没有更多”去看 Opus 4.8,很容易看偏。它真正动刀的地方,是复杂 Agent 任务里最烦人的几件事:多步任务能不能收敛,代码修改能不能验证,模型知道不知道自己哪里没把握,以及团队能不能把高算力模式纳入日常成本表。
一句话概括:Opus 4.8 不是为了让模型看起来更会聊天,而是为了让它在长链路任务里更像一个愿意交付、会复核、知道风险边界的工程执行者。
先看结论:Opus 4.8 赢在复杂闭环,不赢在所有场景
如果只想快速选型,可以把三款模型粗略分成三类:
所以 **Opus 4.8 不是“所有维度碾压”**。它的优势很明确:更复杂、更长、更需要自我校验的任务,它更值得上;如果只是终端里小步快跑,GPT-5.5 依然很有吸引力;如果已有流程跑得稳,Opus 4.7 也没有突然过时。
规格变化不热闹,但工程含义很重
Opus 4.8 的标准 API 价格仍是输入 5 美元、输出 25 美元每百万 tokens,和 Opus 4.7 持平。这个信息比看起来更重要:Anthropic 没有把新旗舰做成“涨价换性能”。
真正值得盯的是 Fast mode。Opus 4.8 Fast 调整到输入 10 美元、输出 50 美元每百万 tokens;相比上一代高性能快链路,价格下探很多。它不再像一个偶尔救火才开的奢侈开关,而是可以进入团队的任务成本模型。
这里的变化不是“便宜了一点”这么简单。对企业团队来说,模型是否能进入流水线,取决于它能不能被预算化。Prompt Caching、Batch API、地域推理溢价这些条款,往往比单次 demo 的表现更决定最终采用率。
Opus 4.8 的 Fast mode 价格下探后,团队终于可以更认真地问一个问题:这类任务多花一点 token 和时延,换更高完成率,是否划算?以前这个问题经常不用算,因为太贵。
Benchmark 里的信号:它更擅长把任务做完
公开指标里,有三组数字最能说明 Opus 4.8 的定位。
这三项放在一起,结论很清楚:Opus 4.8 的强项不是“终端里每一步都最快”,而是“复杂任务更容易走到可交付结果”。
SWE-bench Pro 尤其值得看。它不是让模型补一个玩具函数,而是要求模型在真实代码库里理解上下文、改多个文件、跑验证、修问题。Opus 4.8 在这类测试里领先,说明它在“读仓库 → 拆问题 → 写 patch → 自检”的链路上更稳。
但 TerminalBench 2.1 又把另一个事实摆出来:GPT-5.5 在终端型编码里仍然更强。它更像一个反应快、手感猛、愿意快速推进的 CLI 搭档。Opus 4.8 则更像一个不会那么着急、但更愿意把事情查清楚再交付的工程同事。
选型不要问“哪个更聪明”,要问失败成本有多高
更实用的模型选择方式,不是把所有分数加权求和,而是先判断任务失败一次的代价。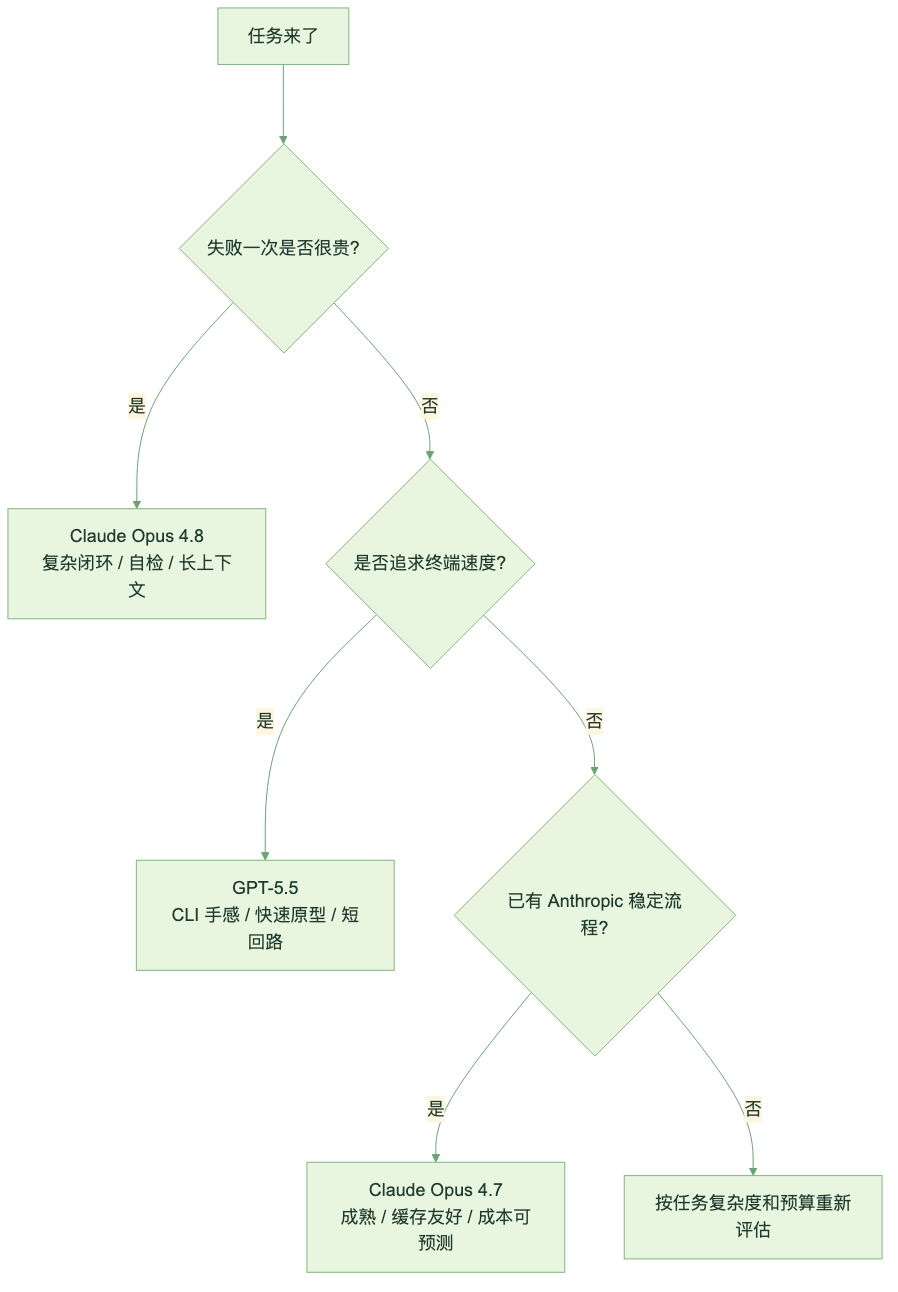
图:按失败成本、终端速度和既有流程选择模型。
如果任务失败会带来昂贵返工,比如跨模块重构、核心业务代码、金融分析、法律材料、长链路 Agent 执行,Opus 4.8 的价值会更明显。它慢一点、贵一点,可能反而省钱,因为少返工。
如果任务允许快速试错,比如写脚本、搭原型、终端里反复跑小改动,GPT-5.5 的速度感更直接。这个场景下,“先冲起来”比“每一步都自证清白”更重要。
如果团队已经在 Opus 4.7 上有稳定工作流,不需要马上追 hardest benchmark,那也没必要为了新模型立刻迁移。4.8 拉高的是上限,不是把 4.7 的地板抽走。
Dynamic Workflows:这次升级最像“Agent 架构能力”的部分
Opus 4.8 配套强调的 Dynamic Workflows,不只是一个新名词。它真正改变的是任务执行方式:模型可以在运行中拆 plan、调子代理、并行探索、汇总冲突,再决定是否重试或交付。
这对 coding 很关键。因为真实软件任务很少是“一问一答”:你要读旧代码、理解约束、生成 patch、跑测试、解释失败、再改一轮。有时还要同时查文档、审查 diff、确认边界条件。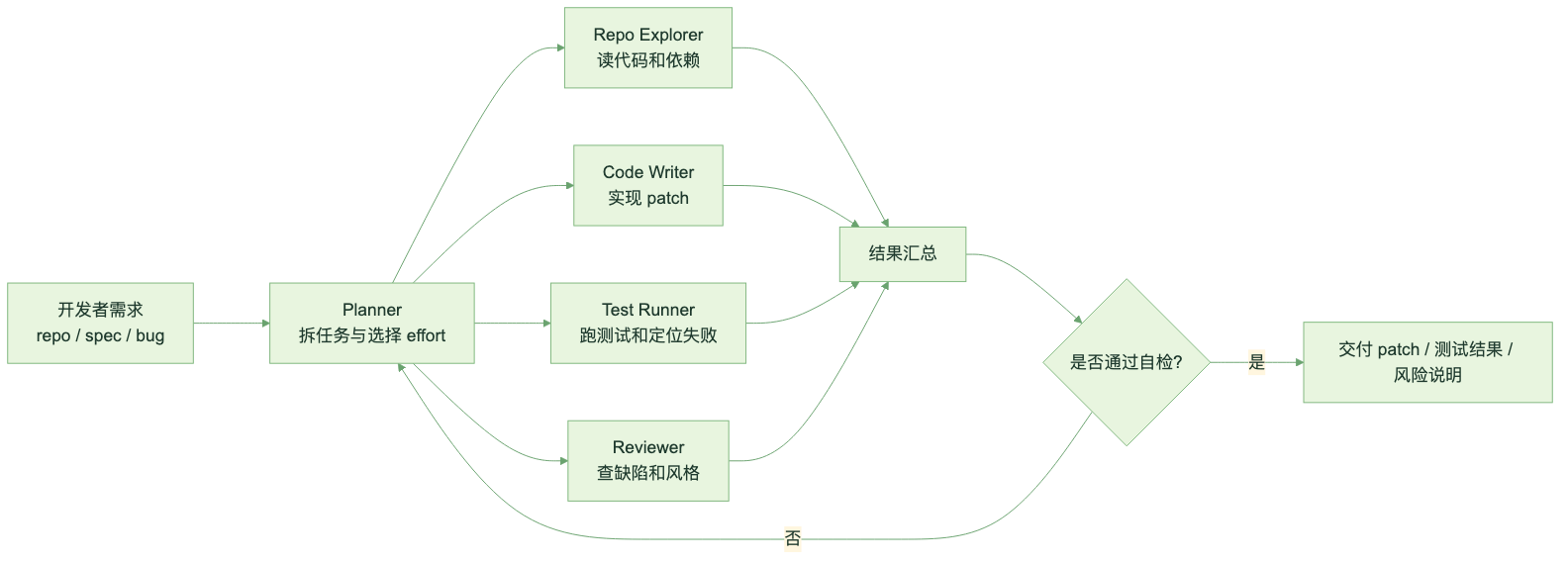
图:Dynamic Workflows 把复杂任务拆成规划、探索、实现、测试和复核。
Dynamic Workflows 的好处是明显的:复杂任务可以被拆开并行处理,模型不必把所有事情塞进一条单线程推理里。
但它也有影子成本。一旦 Planner 的方向错了,多个子代理会一起朝错方向努力,错误扩散速度比过去更快。以前 Agent 跑偏像一个初级工程师犯错;现在更像自动化流水线参数配错,一口气生产出一堆看起来完整但方向不对的结果。
所以 Opus 4.8 越强,团队越需要配套回滚、日志、预算上限和人工 review。否则你得到的不是“更可靠的 Agent”,而是“更快放大的错误”。
图:动态子代理能放大执行效率,也会放大错误方向。
Effort Control:把推理预算从黑箱变成旋钮
Opus 4.8 另一个实际价值,是把 effort 显式化。
过去很多模型也会“更认真地想”,但这种认真常常是黑箱副作用:什么时候多想、想多久、花多少钱,用户事后才从延迟和账单里感受到。
Effort Control 的意义在于,你可以把任务分层:
这对工程组织很重要。模型能力进入生产,不是靠“大家感觉它更强”,而是靠任务类型、预算、延迟和失败成本之间有一套能执行的规则。Opus 4.8 把这件事往前推了一步。
诚实性才是它最容易被低估的能力
Anthropic 把 Honesty / Self-check 放到 Opus 4.8 的核心卖点里,这不是装饰。
很多团队现在不缺“能写代码”的模型。真正消耗时间的是另一件事:模型到底有没有完成?有没有跑测试?有没有把失败藏起来?有没有把不确定的结论说得像已经验证过?
Opus 4.8 的价值在这里变得很具体。官方材料提到,它在代码缺陷检测上相比 4.7 有大幅提升,未发现编码错误的概率下降;外部讨论也普遍把它描述成更愿意暴露风险、更少假装完成的模型。
这种能力不一定让 demo 更炫,但会让生产环境更省心。一个模型如果能主动说:这里没验证、这个假设可能错、这段 patch 需要额外测试,它的工程价值会比单纯“写得快”高很多。
图:诚实性让模型把不确定性暴露给工程流程,而不是藏在交付结果里。
这也是 Opus 4.8 和 GPT-5.5 的风格分歧。GPT-5.5 更像冲刺型选手:推进快,试错快,工具链顺。Opus 4.8 更像审慎型执行者:慢一点,但更愿意把风险摊开讲。
三款模型各自的隐藏税
没有免费的优势。三款模型都要交税,只是税种不同。
如果团队只盯显性价格,会误判。真正该算的是:一次失败要返工多久?一次跑偏会影响多少文件?一次不诚实的“已完成”会让人类 review 多花多少时间?
Opus 4.8 的护城河:不是单项第一,而是组合拳
Opus 4.8 最强的地方,不是某一个 benchmark 数字,而是几件事叠在一起:
这些能力组合起来,才让它在企业级 Agent 任务里更像一个生产模型。
但它也不是无脑首选。Opus 4.8 的优势需要几个前提:任务足够复杂,团队能承受更高 token 和延迟,工作流里有日志、回滚、review 和预算控制。如果这些条件不成立,它的优势会被削弱。
结语:4.8 的关键词不是“更大”,是“更可交付”
Claude Opus 4.8 这次升级,最值得记住的不是窗口、参数或某个单项分数,而是 Anthropic 明确把模型往“复杂任务交付系统”方向推了一步。
它更适合那些失败成本高、需要多步计划、需要验证和自报风险的任务。它不一定让每一次交互都最快,但会让复杂任务更有机会走到一个可信的终点。
如果说 GPT-5.5 更像一个终端里跑得很快的工程师,Opus 4.8 更像一个会先拆方案、调人手、查风险、最后带着测试结果来交付的技术负责人。
这不是谁完全取代谁的问题。模型选型正在从“哪个最强”变成“哪个失败模式最适合我的业务”。在这个维度上,Opus 4.8 的答案很清楚:少一点炫技,多一点交付。
推荐阅读
RAG 负责召回,LLM Wiki 负责沉淀:团队知识系统为什么不能只做检索
Agent Harness 架构真相:Prompt Cache 如何决定 Skill、MCP 与 SubAgent 设计
Claude Code 如何压缩上下文:Microcompact、Prompt Cache 与 cache_edits 工程拆解
为什么 AI Coding 难进生产环境?深入了解 Everything-Claude-Code!
当用户觉得 Agent 变笨时,真正退化的往往不是模型